
cubes.piws.importer.processings.Processings¶
-
class
cubes.piws.importer.processings.Processings(session, project_name, center_name, processings, processing_type, can_read=True, can_update=False, data_filepath=None, use_store=True, piws_security_model=True, check_assessment_with_rql=False)[source]¶ This class enables us to load the processing data to CW.
-
__init__(session, project_name, center_name, processings, processing_type, can_read=True, can_update=False, data_filepath=None, use_store=True, piws_security_model=True, check_assessment_with_rql=False)[source]¶ Initialize the Processings class.
Parameters: session: Session (mandatory) :
a cubicweb session.
project_name: str (mandatory) :
the name of the project.
center_name: str (mandatory) :
the center name.
processings: dict of list of dict (mandatory) :
the processing description: the first dictionary contains the subject name as keys and then a list of dictionaries with two keys ( Assessment - Processings) that contains the entities parameter decriptions.
processing_type: str (mandatory) :
a processing type used to gather together similar processings.
can_read: bool (optional, default True) :
set the read permission to the imported data.
can_update: bool (optional, default False) :
set the update permission to the imported data.
data_filepath: str (optional, default None) :
the path to folder containing the current study dataset.
use_store: bool (optional, default True) :
if True use an SQLGenObjectStore, otherwise the session.
piws_security_model: bool (optional, default True) :
if True apply the PIWS security model.
check_assessment_with_rql: bool (optional, default False) :
if True check if the Assessment entity already exists using an rql.
Notes
Here is an axemple of the definiton of the ‘processings’ parameter:
processings = { "subjects1": [ { "Assessment": { "identifier": u"toy_V1_subject1", "timepoint": u"V1"}, "Processings": [ { "Inputs": ["Any X Where X is Scan"], "ExternalResources": [[{ "absolute_path": True, "name": u"p1", "identifier": u"toy_V1_subject1_p1_1", "filepath": u"/tmp/demo/V1/subject1/images/t1/t1.nii.gz"}]], "FileSets": [{ "identifier": u"toy_V1_subject1_p1", "name": u"p1"}], "ProcessingRun": { "identifier": u"toy_V1_subject1_p1", "name": u"p1", "label": u"segmentation", "tool": u"spm", "version": u"8.1", "parameters": u"{'a': 1, 'r': 'mypath'}"} } ] } ] }
Depreciated example:
processings = { "subjects1": [ { "Assessment": { "identifier": u"toy_V1_subject1", "timepoint": u"V1"}, "Processings": [ { "Inputs": ["Any X Where X is Scan"], "ExternalResources": [ { "absolute_path": True, "name": u"p1", "identifier": u"toy_V1_subject1_p1_1", "filepath": u"/tmp/demo/V1/subject1/images/t1/t1.nii.gz"}], "FileSet": { "identifier": u"toy_V1_subject1_p1", "name": u"p1"}, "ProcessingRun": { "identifier": u"toy_V1_subject1_p1", "name": u"p1", "label": u"segmentation", "tool": u"spm", "version": u"8.1", "parameters": u"{'a': 1, 'r': 'mypath'}"} }] } ] }
Methods
__init__(session, project_name, center_name, ...)Initialize the Processings class. cleanup()Method to cleanup temporary items and to commit changes. import_data()Method that import the processing data in the db. schema(outfname[, text_font, node_text_size])Create a view of the schema described in a python structure. Attributes
assessment_relationsdevice_relationsfileset_relationsrelations-
__module__= 'cubes.piws.importer.processings'¶
-
_create_processing(processing_struct, fset_structs, extfiles_structs, scores, processing_inputs, subject_eid, study_eid, assessment_eid)[source]¶ Create a processing and its associated relations.
-
import_data()[source]¶ Method that import the processing data in the db.
Note
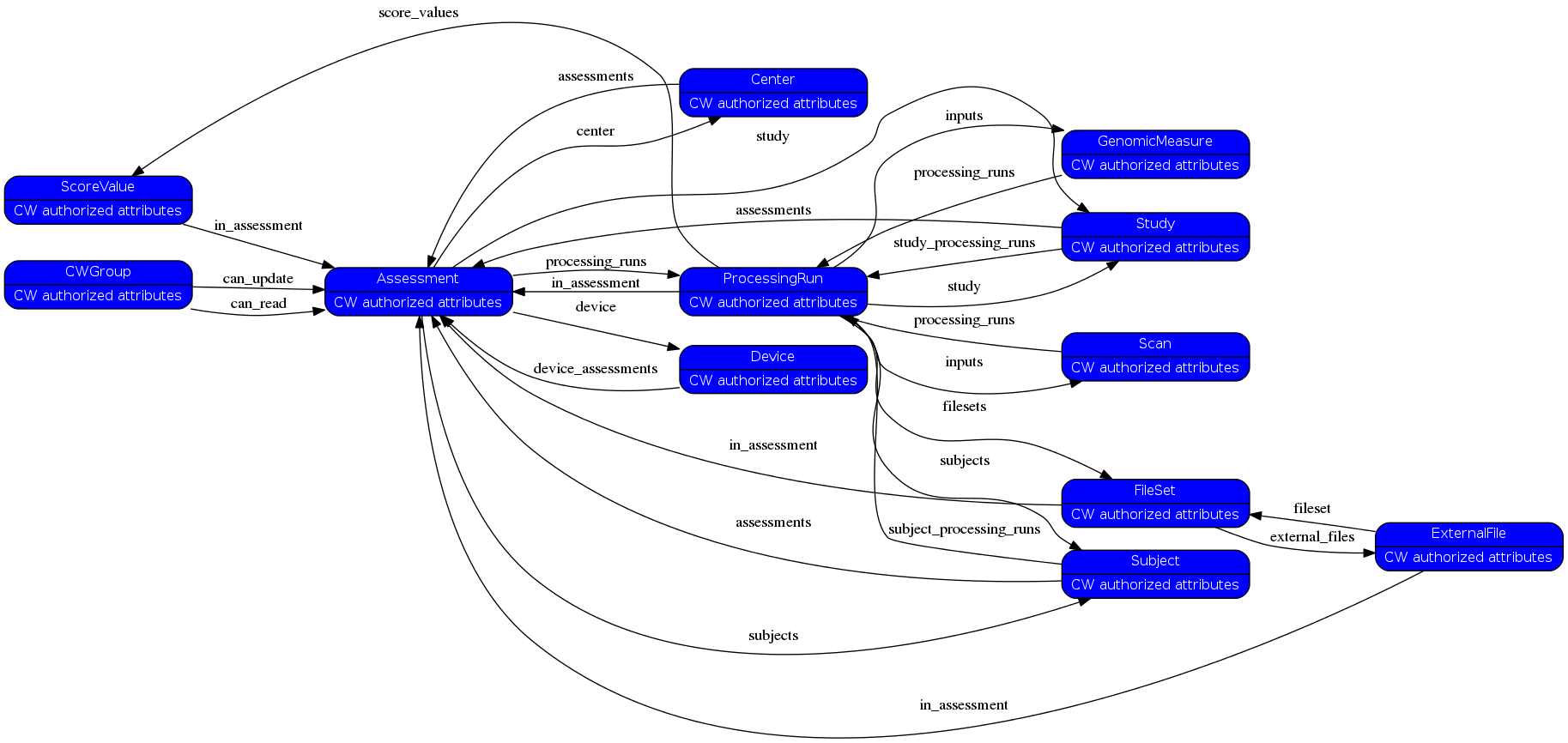
Below the schema used to insert the scans:
Warning
This method assumes that all the subjects and groups have already been inserted in the database.
-
relations= [['Scan', 'filesets', 'FileSet'], ('FileSet', 'in_assessment', 'Assessment'), ('FileSet', 'external_files', 'ExternalFile'), ('ExternalFile', 'fileset', 'FileSet'), ('ExternalFile', 'in_assessment', 'Assessment'), ('Assessment', 'study', 'Study'), ('Study', 'assessments', 'Assessment'), ('Subject', 'assessments', 'Assessment'), ('Assessment', 'subjects', 'Subject'), ('Center', 'assessments', 'Assessment'), ('Assessment', 'center', 'Center'), ('CWGroup', 'can_read', 'Assessment'), ('CWGroup', 'can_update', 'Assessment'), ('Assessment', 'device', 'Device'), ('Device', 'device_assessments', 'Assessment'), ('ProcessingRun', 'study', 'Study'), ('Study', 'study_processing_runs', 'ProcessingRun'), ('ProcessingRun', 'subjects', 'Subject'), ('Subject', 'subject_processing_runs', 'ProcessingRun'), ('Assessment', 'processing_runs', 'ProcessingRun'), ('Scan', 'processing_runs', 'ProcessingRun'), ('GenomicMeasure', 'processing_runs', 'ProcessingRun'), ('ProcessingRun', 'inputs', 'GenomicMeasure'), ('ProcessingRun', 'inputs', 'Scan'), ('ProcessingRun', 'in_assessment', 'Assessment'), ('ProcessingRun', 'score_values', 'ScoreValue'), ('ScoreValue', 'in_assessment', 'Assessment')]¶
-