
Massive univariate linear model.
Brain & age statistics residuallization¶
Credit: E Duchesnay
# General
import os
import os.path
import glob
import numpy as np
import pandas as pd
import urllib.request
import tempfile
# Images
import nibabel
import nilearn
import nilearn.image
import nilearn.plotting
# MULM
import mulm
# ML
from sklearn import linear_model
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_validate
from sklearn import metrics
WD = tempfile.gettempdir()
# WD = '/home/ed203246/data/brain_age_ixi'
os.makedirs(os.path.join(WD, "data"), exist_ok=True)
Download ixi anatomical VBM dataset¶
def fetch_data(files, dst, base_url, verbose=1):
"""Fetch dataset.
Args:
files (str): file.
dst (str): destination directory.
base_url (str): url, examples:
ftp://ftp.cea.fr/pub/unati/share/anat
Returns:
downloaded ([str, ]): paths to downloaded files.
"""
downloaded = []
for file in files:
src_filename = os.path.join(base_url, file)
dst_filename = os.path.join(dst, file)
if not os.path.exists(dst_filename):
if verbose:
print("Download: %s" % src_filename)
urllib.request.urlretrieve(src_filename, dst_filename)
downloaded.append(dst_filename)
return downloaded
fetch_data(files=['train_participants.csv', 'train_rois.csv', 'train_vbm.npz',
'validation_participants.csv', 'validation_rois.csv', 'validation_vbm.npz',
'mni_cerebrum-mask.nii.gz'],
dst=os.path.join(WD, "data"),
base_url='ftp://ftp.cea.fr/pub/unati/people/educhesnay/data/brain_anatomy_ixi/data',
verbose=1)
datasets = dict()
for filename in glob.glob(os.path.join(WD, "data", "*.npz")):
imgs_arr_zip = np.load(filename)
datasets[os.path.splitext(os.path.basename(filename))[0]] = \
imgs_arr_zip['imgs_arr']
demo_train = pd.read_csv(os.path.join(WD, "data/train_participants.csv"))
demo_val = pd.read_csv(os.path.join(WD, "data/validation_participants.csv"))
# VBM
imgs_train = datasets['train_vbm'].squeeze()
imgs_test = datasets['validation_vbm'].squeeze()
print(imgs_train.shape, imgs_test.shape)
# Read mask
mask_img = nibabel.load(os.path.join(WD, "data", "mni_cerebrum-mask.nii.gz"))
mask_arr = mask_img.get_fdata() != 0
# Apply mask
X_train = imgs_train[:, mask_arr]
X_test = imgs_test[:, mask_arr]
Out:
(357, 121, 145, 121) (90, 121, 145, 121)
Univariate statistics¶
Z_train, t_contrasts, f_contrasts = mulm.design_matrix(formula="sex + age", data=demo_train)
mod_mulm = mulm.MUOLS(Y=X_train, X=Z_train).fit()
def flat_to_img(mask_img, flat_values):
val_arr = np.zeros(mask_img.get_fdata().shape)
val_arr[mask_img.get_fdata() != 0] = flat_values.squeeze()
return nilearn.image.new_img_like(mask_img, val_arr)
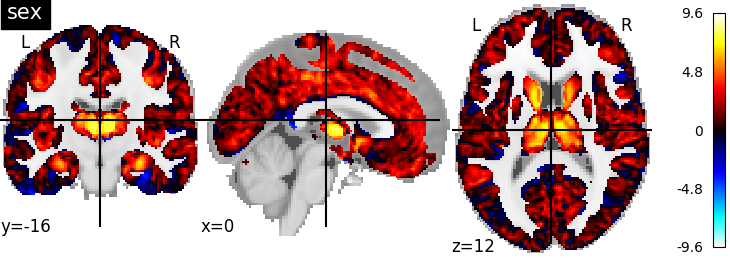
tstat_sex, pval_sex, df_sex = mod_mulm.t_test(t_contrasts['sex'], pval=True)
tstat_sex_img = flat_to_img(mask_img, tstat_sex.squeeze())
nilearn.plotting.plot_stat_map(tstat_sex_img, title="sex")
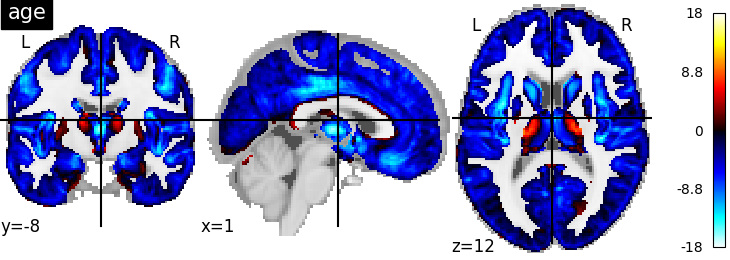
tstat_age, pval_age, df_age = mod_mulm.t_test(t_contrasts['age'], pval=True)
tstat_age_img = flat_to_img(mask_img, tstat_age.squeeze())
nilearn.plotting.plot_stat_map(tstat_age_img, title="age")
Residualize on sex adjusted on age to predict the age using sklearn¶
from mulm.residualizer import Residualizer
from mulm.residualizer import ResidualizerEstimator
lr = linear_model.Ridge(alpha=1)
scaler = StandardScaler()
cv = KFold(n_splits=5, random_state=42)
y_train = demo_train["age"].values
residualizer = Residualizer(data=demo_train, formula_res='sex',
formula_full='sex + age')
# Extract design matrix and pack it with X
Z_train = residualizer.get_design_mat(data=demo_train)
# Wrap the residualizer
residualizer_wrapper = ResidualizerEstimator(residualizer)
ZX_train = residualizer_wrapper.pack(Z_train, X_train)
pipeline = make_pipeline(residualizer_wrapper, StandardScaler(), lr)
cv_res = cross_validate(estimator=pipeline, X=ZX_train, y=y_train, cv=cv, n_jobs=5,
scoring=['r2', 'neg_mean_absolute_error'])
r2 = cv_res['test_r2'].mean()
mae = np.mean(-cv_res['test_neg_mean_absolute_error'])
print("CV R2:%.4f, MAE:%.4f" % (r2, mae))
Out:
CV R2:0.8183, MAE:5.2592
Total running time of the script: ( 0 minutes 51.952 seconds)
Gallery generated by Sphinx-Gallery
Follow us
© 2021,
pylearn-mulm developers
.
Inspired by AZMIND template.
Inspired by AZMIND template.